


PetCheck
Designing a Scalable Care-Tracking System That Grows Without Breaking
Role: Product Manager & Builder (Low-code)
Platform: iOS (FlutterFlow + Firebase)
Scope: Data modeling · Information architecture · Performance · Multi-actor systems
Product Point of View
Pet care products naturally want to sprawl: more routines, more reminders, more caregivers, more data over time. Left unchecked, that scope creep quickly degrades both system performance and user experience.
PetCheck was designed to answer a specific product question:
How do you build a care-tracking system that can expand in scope without becoming slow, brittle, or cognitively overwhelming?
From the start, I treated backend architecture and frontend information design as coupled product decisions. The guiding principle was simple:
If the backend stays bounded and coherent, the frontend can stay fast, calm, and human.
That principle drove two parallel strategies:
Keep the backend nimble as scope grows
Keep the frontend lightweight as complexity increases
Constraints
PetCheck was built under real, non-ideal constraints:
Solo PM and builder
Low-code tooling (FlutterFlow)
Mobile performance limits
Cost sensitivity around database reads/writes
Privacy-first expectations
A domain with inherently recurring and long-lived data
The challenge was not feature ideation. It was preventing architectural debt while shipping.
Strategy 1: Keeping the Backend Nimble as Scope Grows
The Problem: Recurring Data Explosion
Pet care involves routines that repeat daily or weekly. A naïve approach would store every future occurrence indefinitely, which leads to:
Unbounded document growth
Slower queries over time
Rising operational costs
Degraded “Today” experiences
The Decision: Rolling Window for Generated Data
Instead of storing every future routine occurrence, PetCheck maintains a rolling two-week window of active occurrences.
Occurrences are generated just-in-time
Past occurrences are safely discarded
Query size remains predictable
Storage growth is bounded
This keeps the system performant while still feeling “always current” to the user.
Rolling Occurrence Window Diagram
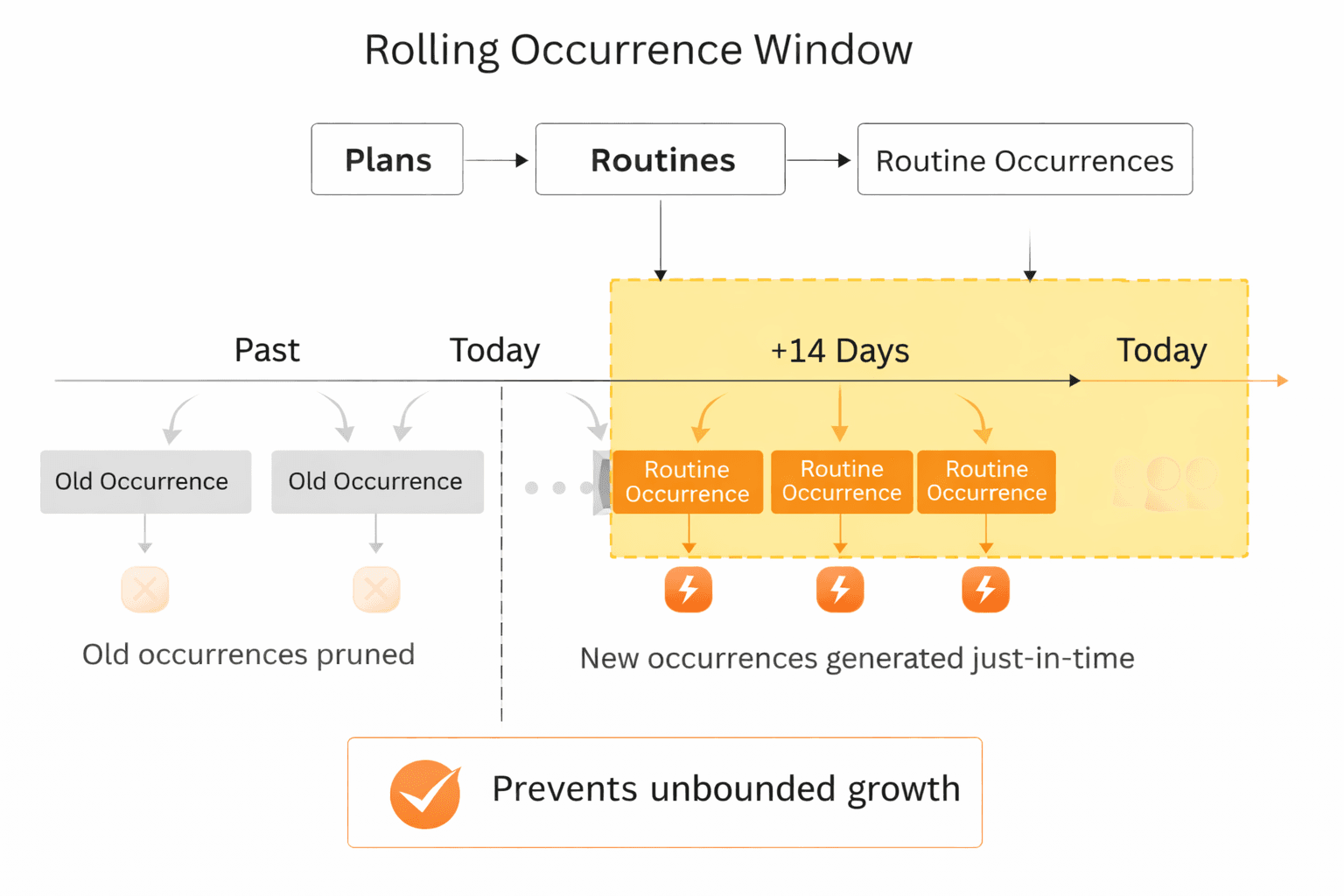
Plans → Routines → Routine Occurrences
A highlighted 14-day window
Old occurrences being pruned
New occurrences generated as the window advances
Callout: “Prevents unbounded growth”
Strategy 2: Schema Design as a Scaling Constraint
Rather than optimize for speed of implementation, the data model was designed around clear ownership and lifecycle boundaries.
Core Schema Concepts
Plans → high-level intent (e.g. Skin Care, New Puppy)
Routines → structured repetition
Routine Occurrences → generated, disposable artifacts
Logs → durable signal data
Generated data is disposable. User-authored signal is preserved.
This separation ensured that adding features would compose cleanly rather than require rewrites.
Schema / Entity Relationship Diagram
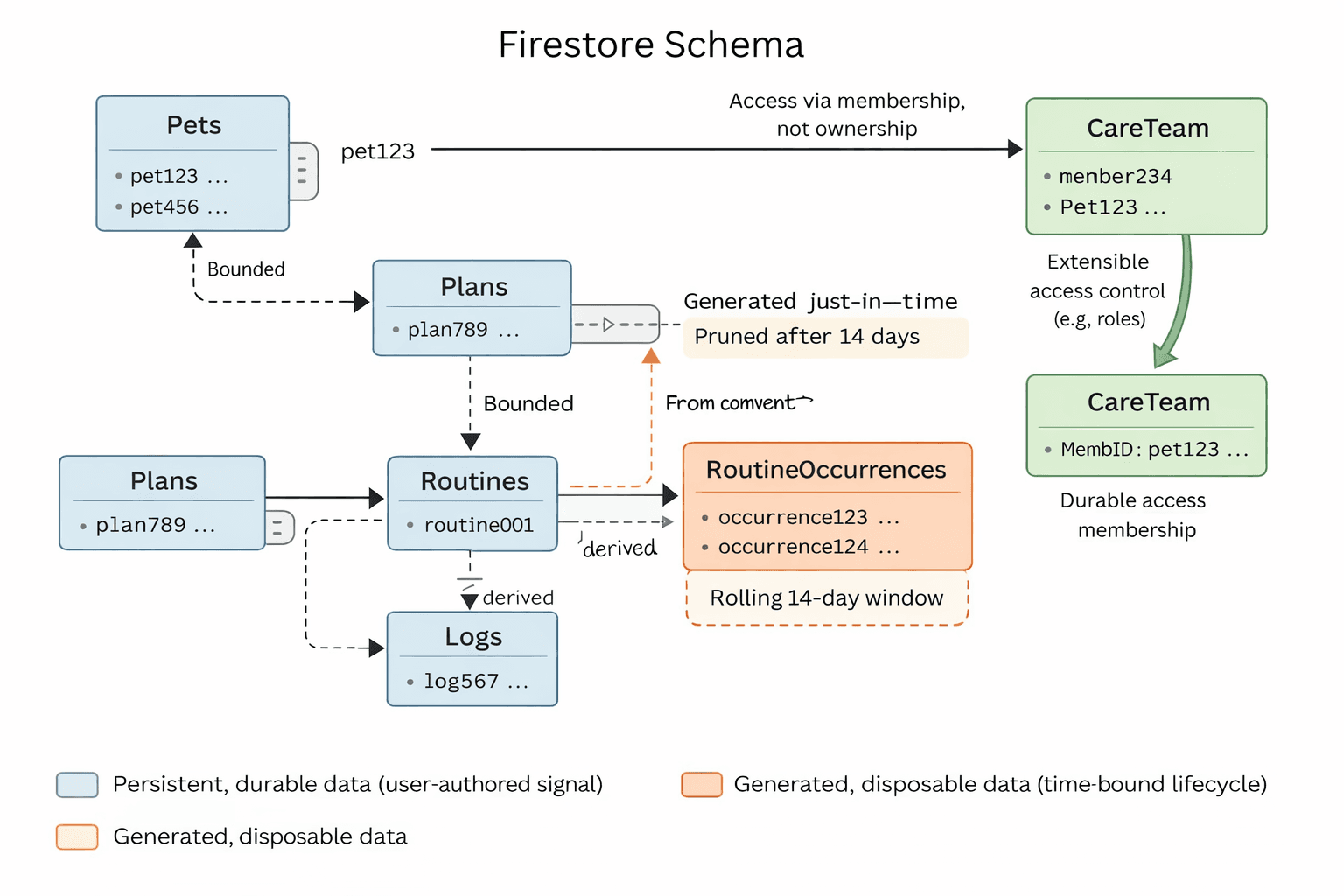
Plans → Routines → RoutineOccurrences → Logs
Clear separation between durable and generated data
Lifecycle annotations (persistent vs disposable)
Care Team as a separate access layer
Proof: Multi-Caregiver Expansion Without Refactor
As PetCheck expanded beyond a single owner, the schema was tested under real feature growth.
Rather than duplicating pets or overloading ownership fields, I introduced a Care Team membership model:
Pets are no longer tied to a single owner
Access is granted via membership
Roles and permissions can evolve independently
Because the schema was already normalized and bounded:
No major refactors were required
No performance regressions occurred
Frontend complexity stayed contained
This validated the original premise: disciplined schema design enables confident expansion.
Care Team Invite & Access Flow
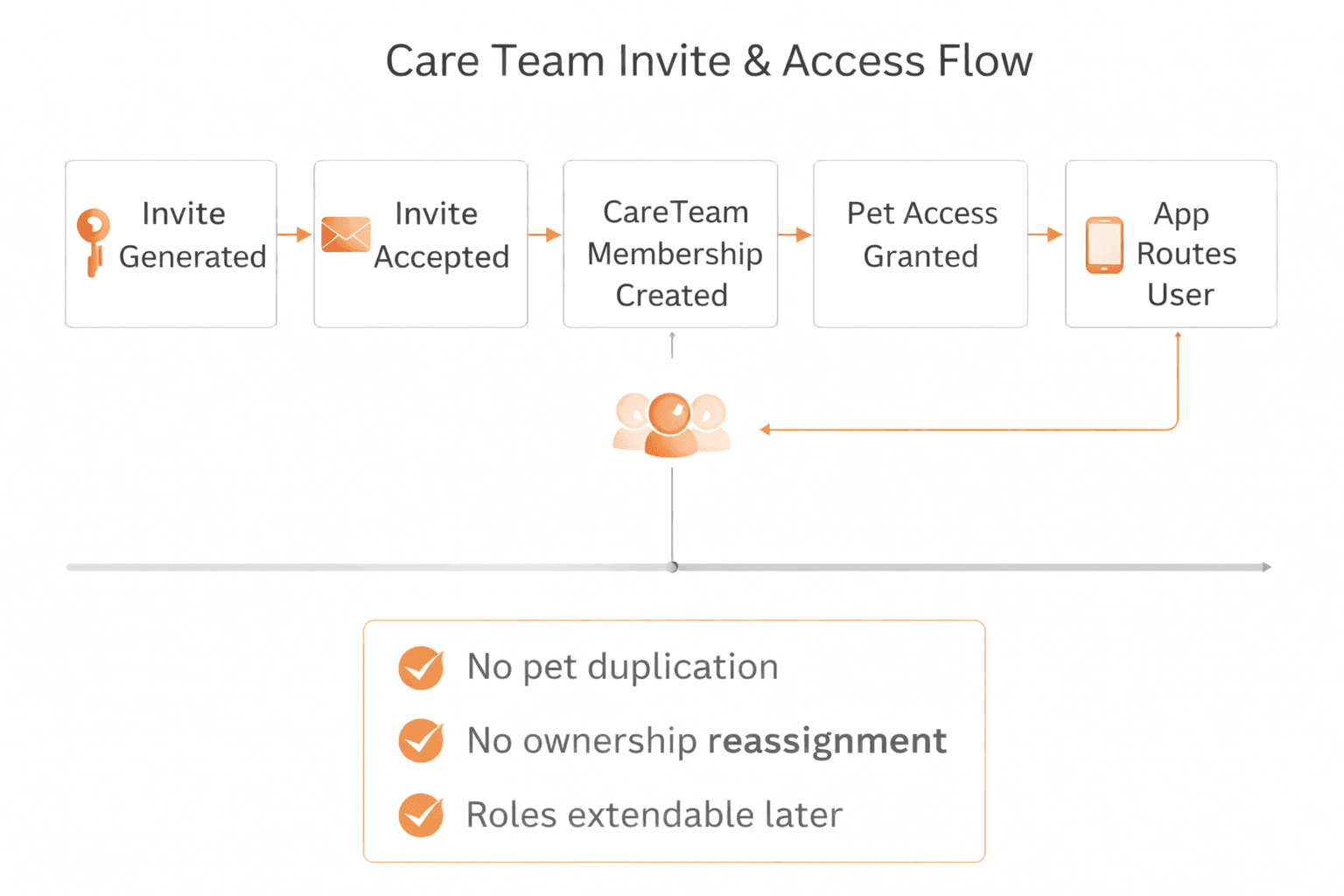
Invite token generation
Pending invite resolution
Care Team document creation
Access propagation without pet duplication
Strategy 3: Frontend Design That Mirrors the System
On the frontend, the goal was not “fewer clicks,” but lower cognitive load for the highest-frequency actions.
Quick Logging as the Primary Interaction
Logging is the most common action in PetCheck. It was designed to be:
Fast
Low-friction
Emotionally lightweight
Most logs resolve in a single tap or short flow, supporting daily habit formation.
Information Architecture as a Constraint
The tab structure mirrors the backend model:
Check-In → capture signal
Insights → interpret patterns
Care / Medical → configure structure
Profile → administer
This separation ensures that configuration complexity does not leak into daily use.
IA → Data Mapping
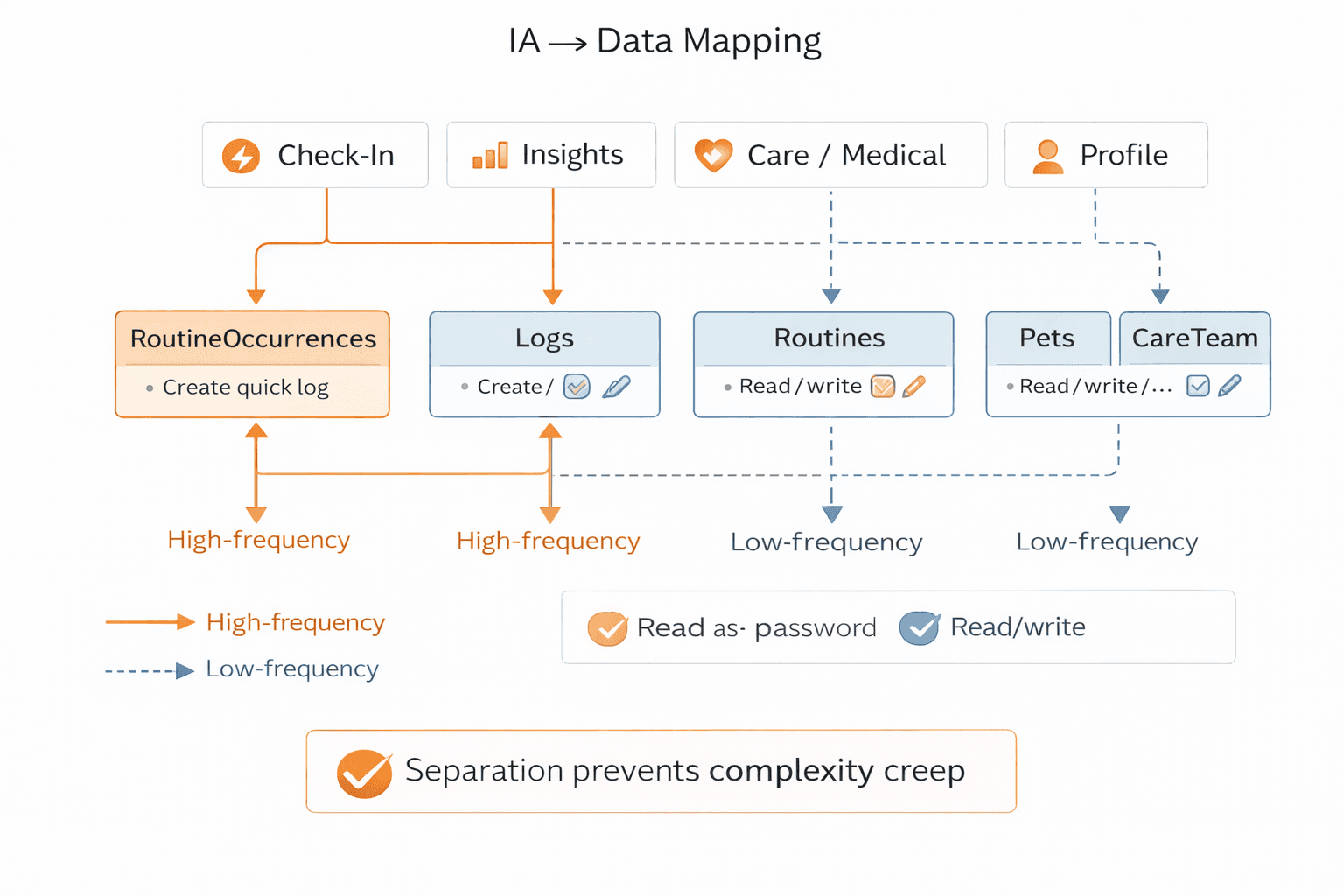
Each tab
The collections it reads/writes
High-frequency vs low-frequency actions
Why separation prevents complexity creep
Reliability & Guardrails in a Low-Code Environment
Working in FlutterFlow required explicit system guardrails:
Idempotent generation of occurrences
Unique keys to prevent duplicate writes
Conditional gating for null or partial states
Query shaping to keep the “Today” view fast
Several production issues (duplicate occurrences, loading loops, query misuse) were resolved by tightening schema rules and action chains rather than adding UI workarounds.
Outcome
PetCheck shipped as a working MVP with:
Recurring schedules that scale without data explosion
Multi-caregiver support without schema rewrites
Fast, low-friction daily logging
An architecture that remains extensible rather than brittle
More importantly, the system is designed so that future scope increases do not require foundational rework.
Takeaway
PetCheck is not presented as a polished end state. It exists to demonstrate how I think and make tradeoffs when building under real constraints:
Designing for performance before it breaks
Treating schema and IA as product decisions
Preventing scope creep from becoming technical debt
Shipping responsibly on imperfect tools
This is the case study that shows I can speak fluently with engineers, reason about systems, and design products that scale thoughtfully.


